ChatGPT for Web Developers
Unveiling the Potential of AI-Powered Assistance with your web content and the ChatGPT browsing plugin
 by Maximiliano Firtman
by Maximiliano Firtman
About 11 min reading time
If you're a web developer, you might be wondering how the recent rise of ChatGPT impacts your work. In this article, we'll discuss practical ways you can improve your website or web app to support this AI technology. We'll also take a closer look at the new ChatGPT browsing plugin and how it works.
TL;DR #
You could ask an AI to summarize this article. But just for fun, let's do it one more time in a human way 😜
- ChatGPT can now browse your website if the user's question includes your site URL or name
- ChatGPT can search on the web using Bing and find content from your website
- The browser only reads and extracts text from your URLs
- All client-side content rendered with JavaScript is ignored
- You can request ChatGPT not to use your content
- You can optimize your content for AI
- You can also integrate ChatGPT in your apps with plugins or using OpenAI APIs

From the beginning #
Everyone knows what's ChatGPT, but sometimes we mix concepts. So first, what's ChatGPT? ChatGPT is a product from OpenAI, a private company with a significant partnership with Microsoft. That product is a chat interface to AI models from the same company, such as GPT-3.5 and GPT-4, and support for plugins. It has a free tier, the most famous one, and a Plus account offered today at $15 U.S. dollars per month.
The GPT models behind ChatGPT are LLMs -Large Language Models-, AI models trained to complete sentences, similar to the autocomplete mechanism in your mobile virtual keyboard that guesses what's the most probable next word that comes next (but extremely more potent than them). Other LLMs are LLaMA from Meta and PaLM from Google, the one powering Google Bard, ChatGPT's main competitor.
Also, GPT models from OpenAI empower Bing Chat and other Microsoft-related AI products. In this article, we will focus on ChatGPT in particular.
But you are a web developer or a web designer. What's in for you?
We can organize abilities and optimizations in three sections:
- ChatGPT browsing your website
- ChatGPT plugin development
- Integrating GPT into your webapp.
In this article, we will focus on the ChatGPT browsing plugin. If you want to learn more about plugins and AI integration for your website, let me know on Twitter.
The Black GPT Box #
GPT models are simple from the outside. They are just an opaque black box receiving a string as input (the prompt), and they send us back an output (a response). We don't know what happens within the box, so our only arguments are the prompt and some basic parametrization that we can set.

The ChatGPT browsing plugin #
ChatGPT is now offering every Plus user the ability to enable the Web browsing plugin.
I asked ChatGPT how it works, and this is its first answer:
"I use a simplified text-based browsing tool that can fetch the contents of web pages and present them as text. It doesn't support JavaScript or other interactive web technologies, and it doesn't have a version number like a traditional web browser would. However, it allows me to pull in information from the web that was published after my training data was cut off in September 2021."
If you are a Plus user and it's not working, enable it from Settings, Beta features, Web browsing. It works only on the website, not in the native official apps.
Then, based on the user's question, ChatGPT can browse websites and have essential interaction with them to enhance the response from the model.
When using ChatGPT, you must explicitly select the Web browsing model from the GPT-4 drop-down.

Which browser is it? Is it executing JavaScript? Will my client-side app work? I don't want ChatGPT to consume and deliver my content without the user visiting my website; can I opt out?
Let's answer those questions, but first,
Wait, what? Can ChatGPT browse the web? #
Yes and no
Let me clarify. The GPT models behind ChatGPT can NOT browse the web. They were trained in 2021, and that's all they can do. They can't do anything else than try to complete sentences of text based on their training. It seems simple, but it can be helpful for many tasks, including writing code. But they can't browse the web, so it's a NO. But you are still reading this paragraph, waiting for the yes.
We already mention that there is a ChatGPT Browsing plugin available. Is it a *YES(), then? Can it browse the web?
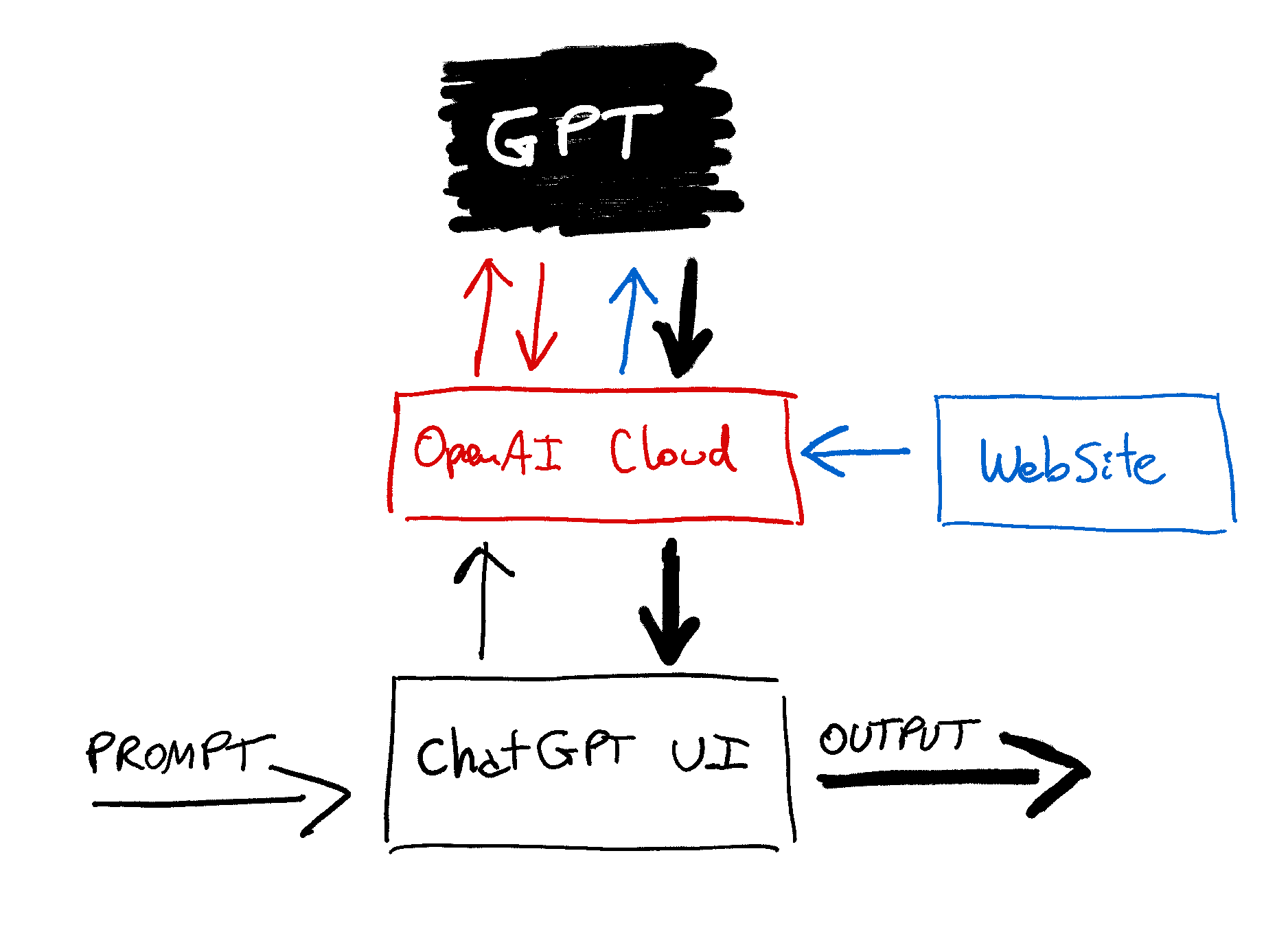
The model behind ChatGPT can't browse the web, but the ChatGPT backend can browse the web before prompting the model, and that's where the trick lives.
If ChatGPT thinks you are providing a URL or asking for something that can be retrieved from the web, it will go to the website, "browse" it, extract its content, and inject the text as part of the final prompt to the model. It's like doing copy/paste of the web's text into the prompt, but automatically.
Compatible Content #
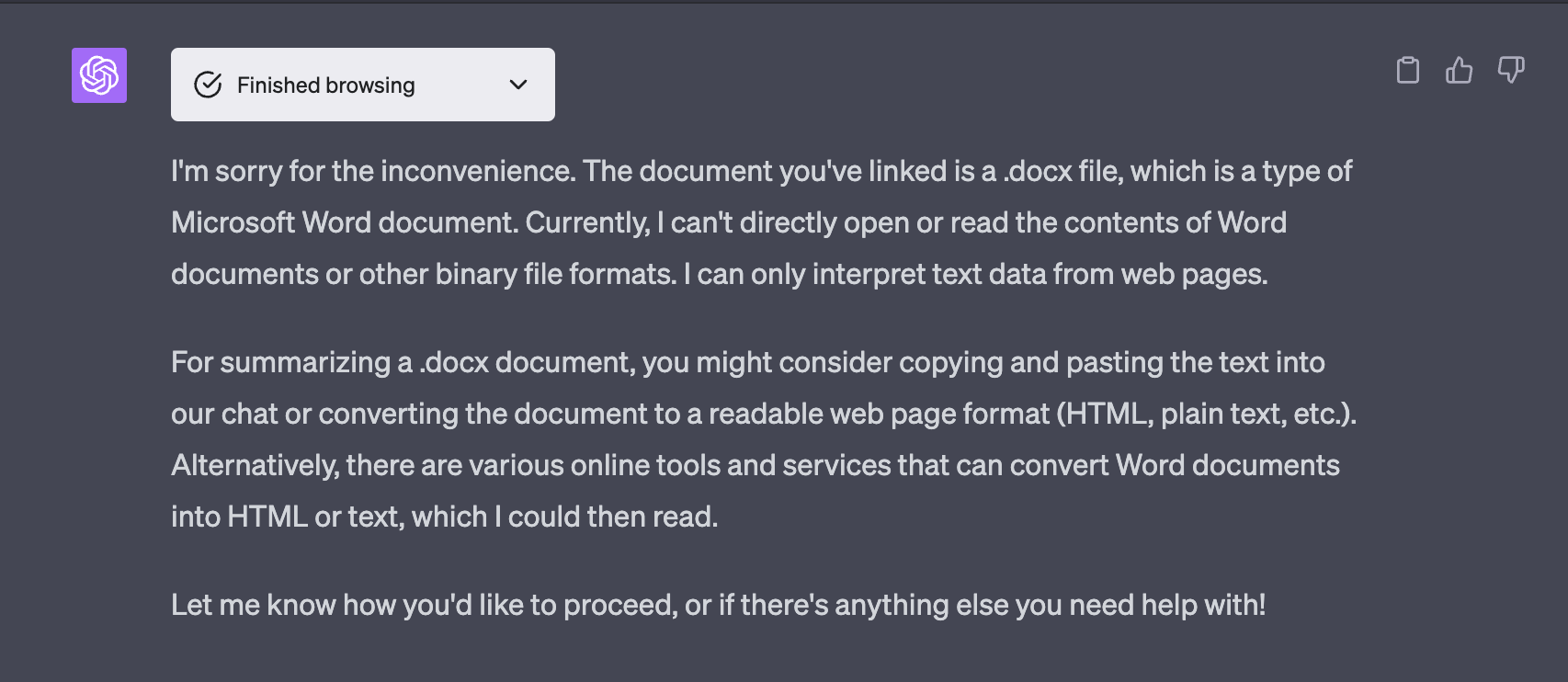
While Bing Chat and Google Bard can read many types of files, ChatGPT rejects HTTP responses with binary documents, such as PDF or DOC files. It accepts HTML or plain text files and should be hosted in a public URL with no authentication.
ChatGPT Browser Detection #
You can detect server-side that ChatGPT is browsing your website to inject your content into a user's prompt.
After that detection, there are three decisions you can make: opt-out, optimize for AI, or do nothing.
The most common situation is to do nothing. ChatGPT will use your content as a source of information for whatever the user is asking, and the user will receive a cite with a link to your URL that will be opened in the standard browser.
Opt-out #
If you prefer not to feed ChatGPT with your content, you can opt-out, and the system will honor your decision. To opt-out, you have to use the old friend robots.txt, a file you place in the root folder of your domain that specifies rules for bots, such as search engines and now IA engines.
The bot is known as ChatGPT-User, and its entire User Agent string is
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ChatGPT-User/1.0; +https://openai.com/bot
ChatGPT bot uses the string ChatGPT-User, so if you want to opt-out from ChatGPT, you can use robots.txt
User-agent: ChatGPT-User
Disallow: /
If you want to opt-in only for some specific folders or URLs, you can use
User-agent: ChatGPT-User
Allow: /public
Disallow: /hidden-to-ai
Remember that these requests will be made from OpenAI's cloud servers, not from the end-user browser, so you can detect or block these requests by the IP address originating them in the 23.98.142.176/28 range.
If a website denies access to the ChatGPT bot, the user will see a "Click failed" message within the ChatGPT user interface.
Optimizing your content for GPT #
What about optimization? According to OpenAI's documentation, you shouldn't do anything special. Still, if you want to reduce the output or change the format in which you send the response to ChatGPT to increase the opportunity to use your data correctly, you can check the User-Agent. It will contain the string "ChatGPT-User" You can use server-side libraries or server-mapping tools to serve different content.
Will we see AIO in the future? AIO? Artificial Intelligence Optimization :)
Which user actions may trigger a visit to your website? #
There are two prominent use cases for ChatGPT to trigger a visit to your website:
Direct browsing #
When the user asks for information about a specific site or types a URL into the prompt, ChatGPT will try to browse that website and read its content.
Searching the web #
When the user asks for information about events happening after models' training (2021 as of GPT-4) or events that it's unaware of, ChatGPT can search and then click on one or more search results to get the content it's looking for.
ChatGPT uses Bing as its search engine for these cases, and each search may include several navigations. For the prompt "Which are the latest courses published by Maximiliano Firtman?" that we can see in the previous video, these were the probable steps done by ChatGPT browsing:
- First, ChatGPT asked the model if the prompt would be improved by browsing a URL or doing a search, and the model probably answered that searching will help (we don't see this process as it happens server-side).
- ChatGPT searched on Bing, they use the Bing API, not the website
- ChatGPT probably sent the model the search results to find a useful reference for the original prompt (we don't see this process as it happens server-side).
- From the search results, it went to one tweet when I mentioned my latest courses
- That tweet included a link to the firt.dev's website. Then, ChatGPT when to firt.dev
- It may read several URLs on my website and filter only courses to inject that content for the final prompt.
- The model received my original prompt and, as context, HTML content from my website and gave me a final answer
BTW, you can check all my courses here :)
ChatGPT citing your website #
ChatGPT's responses will include a cite and a link back to your website when using your content, but keep in mind users won't be seeing your ads or converting into your website directly, but you will still be paying for the infrastructure.
The cite appears in the output response and the browsing experience's details.

The cite has the origin of your website and your favicon. For some reason, OpenAI takes the icon from DuckDuckGo; in my sample, the URL used is https://icons.duckduckgo.com/ip3/firt.dev.ico.
The link within ChatGPT for the user to visit your website includes an expected target="_blank" and a rel=" no-referrer", which means you won't know that the visit is coming from a cite.
Unfortunately, finding information about ChatGPT in your analytics will be tricky. You won't find analytics about incoming users from ChatGPT's cites. Using a client-side Analytics library, such as Google Analytics, you won't receive any hits from the ChatGPT browsing sessions. You have to use the server's logs to check on User-Agent strings.
Security and Scalability Issues #
The Web browsing plugin can only make GET requests to your servers, removing all POST and other requests that could harm your infrastructure or consume more bandwidth.
Additionally, ChatGPT implemented rate-limiting measures to avoid sending excessive traffic to websites. No details on those limits were published, but we also know that no additional resources are retrieved apart from the main document of each navigation.
There are techniques to trick the model, known as prompt injection. As we mentioned before, the contents of our website are injected into a final prompt that the GPT model uses to answer the user's question. As of today, I don't know any method that could mislead the ChatGPT browser plugin. We've seen some prompt injection on Bing Chat, though.
ChatGPT Browsing Tool Abilities #
First, the Web browsing plugin can only make GET requests to your servers, so that leaves out filling forms or sending data for your user, as of the first version of the plugin.
If you want ChatGPT to operate over your website or app apart from reading content, such as making POST requests, consider developing a ChatGPT Plugin.
When on your website, the ChatGPT browsing plugin can read its text-based content and links; they can follow links and navigate back from them.
If the browsing tool can't handle a URL, the user will see and answer like I apologize for the inconvenience, but it seems the page content cannot be correctly displayed using the browser tool. The tool cannot handle certain types of web content, such as specific JavaScript elements or complex HTML structures.
OpenAI doesn't describe how the browser works, but I did some research to answer some questions, and here are my results.
- ChatGPT doesn't wait for JavaScript to run, and the engine completely ignores any dynamic content, so if you are based on client-side rendering (such as a pure client-side React app), you have a problem with ChatGPT. * It doesn't load any additional resources from the main HTML document, so scripts, styles, and images are not requested. However, it recognizes when the page's content is rendered with JavaScript; I'm wondering if it executes or sees embedded JavaScript or infers it by just analyzing the body of the HTML.
- The length of text it can read is limited, which leads to the maximum size of the prompt currently supported (technically, it's measured in tokens, not in characters); if the webpage is larger than that, the browser starts a "scrolling" operation which means it reads another chunk of data looking for the correct info.
- I'd like to know if a rendering engine is behind the browser tool or if it's just analyzing the body HTTP response with the GPT-4 model. If it's an actual rendering engine, it may be Gecko- or Chromium-based by inferring the WebKit version number used in the user agent (WebKit/537.36). I don't have an answer to this question.
JavaScript Execution #
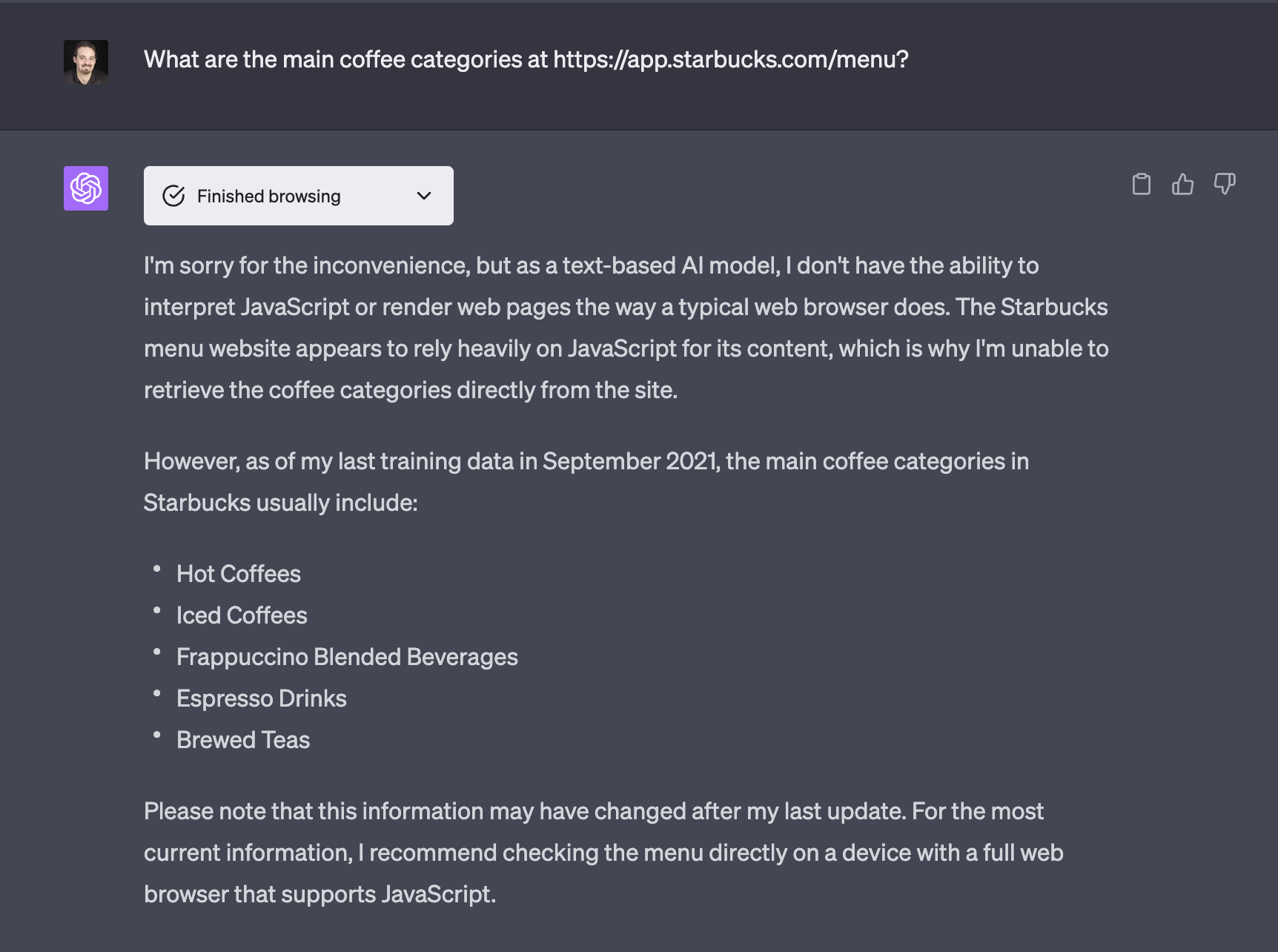
ChatGPT can't wait for JavaScript to run; we can see it directly when I try to run html5test on it. However, it recognizes that the website uses JavaScript to render content.

Also, a client-side web app, such as the Starbucks PWA, has problems with even simple requests, such as the categories of a menu:
Content with Problems #
I've asked ChatGPT, after a failed web crawling experience, what types of content can have problems, and this is the unedited GPT answer:
As an AI, I can access a variety of web content through OpenAI's browser tool. However, there are some limitations to this capability. Here are some types of web content that can be challenging for me to read:
- Dynamic Content: Web content that is generated or altered by JavaScript or other client-side scripts after the page has loaded may not be visible. This includes things like lazy-loaded content, pop-ups, or content that appears after a user interaction (like clicking or hovering).
- Non-text Content: While the browser tool can read and interpret HTML, it doesn't support images, videos, or audio content. It can't interpret image-based text (like infographics or memes), watch videos, listen to audio files, or read Flash or other multimedia content.
- CAPTCHA and Forms: The browser tool cannot fill out forms or pass CAPTCHA verifications.
- Real-Time Updates: Content that updates in real-time (like a live chat or a stock ticker) may not be accurately represented.
- Content behind a Login: Any content that requires a login or other form of authentication to access won't be available to the tool.
- Cookies or Consent Dialogs: Sometimes, a website's content may be obscured by cookies or consent dialogs. The tool can't interact with these dialogs.
- Frames or iFrames: Content within frames or iframes may not be fully accessible.
- PDFs or Documents: The tool might have difficulties with content in PDFs or other document formats that are embedded in a webpage.
Also, when asked about JavaScript, it says:
OpenAI browser tool can handle some JavaScript-generated content that is generated before the page load event, as long as it doesn't involve real-time changes or user interactions. This means that if the JavaScript code generates static content as the page is loading, the tool should be able to read it.
Page Length #
We know the amount of data it can read is limited, so the ChatGPT response regarding this matter is as follows:
The browsing tool can process a substantial amount of HTML content, but there are some limitations. The tool presents the contents of a webpage in a simplified, text-based format, and only a portion of the page's content is displayed at a time. If a webpage is very long, I would need to issue multiple scroll commands to view all of its content. Furthermore, complex HTML structures, scripts, or interactive elements might not be fully represented or functional in the text-based display.
As for the specific maximum length, there isn't a defined character limit for the pages the browser tool can handle. However, the length of individual commands and responses in the AI model's conversation is limited to 4096 tokens. A token can be as short as one character or as long as one word. If a page's content exceeds this limit in a single command/response, it would need to be broken up into smaller pieces.
Inspecting resources #
To confirm that ChatGPT can't read external files, we can see the model response to questions about inspecting additional resources:
I'm sorry for the inconvenience, but as a text-based AI model, I'm unable to directly inspect the source code of websites or count the number of JavaScript and CSS files. My browsing capabilities are primarily focused on viewing and interpreting the text content of web pages, and I don't have the ability to parse or interpret JavaScript, CSS, or other web technologies directly.
Tracing HTTP Headers #
Currently, the ChatGPT browsing agent requests include many trace headers that I wonder if we can use for conversation-tracking purposes.
Here is a sample of headers I've got from one request:
X-Datadog-Tags: _dd.p.dm=-1
Tracestate: dd=s:0
Traceparent: 00-00000000000000009cc46061611549f8-
fedb29ba6158bb85-00
X-Datadog-Sampling-Priority: 0
X-Datadog-Parent-Id: 18364317786007190405
X-Datadog-Trace-Id: 11296259736708925944
Summary #
ChatGPT browsing tool is the first step into browsing with AI. There are other tools to do that, such as Bing Chat and Google Bard can browse the web today.
First, you don't need to do anything special if your content is statically or server-side served. If your content is pure client-side rendering, you have a problem (not just helping AI agents), so you should consider moving it to a different architecture.
If you don't want to serve content to AI users, you can block access to ChatGPT agents. The future of web browsing and search engines is still being determined, so we must adjust techniques and best practices as we move forward with AI.
Did you find anything else? Let me know on Twitter @firt
Disclaimer: A human person wrote this article unless otherwise specified 🤖.